DiffDAIL: Diffusion-Enhanced Vision-Guided Imitation Learning with Discrete Latent Representations#
📝 Abstract#
Robotic imitation learning often struggles with high-dimensional sensory inputs, noisy demonstrations, and computational inefficiency in policy learning. We present Discrete Action Imitation Learning enhanced with Diffusion (DiffDAIL), a vision-guided framework that combines discrete action encoding and diffusion-based representation learning to address these challenges. By discretizing latent embeddings, DiffDAIL reduces computational cost, while a diffusion-based denoising loop improves robustness and captures heterogeneous action distributions. A Transformer-based architecture further models long-range dependencies in sequential decision-making tasks. Experimental results across benchmark manipulation tasks demonstrate that DiffDAIL outperforms conventional VAE-based and diffusion methods, achieving higher task success rates and improved data efficiency. These results highlight DiffDAIL as a scalable, robust, and resource-efficient approach for vision-guided robotic imitation learning.
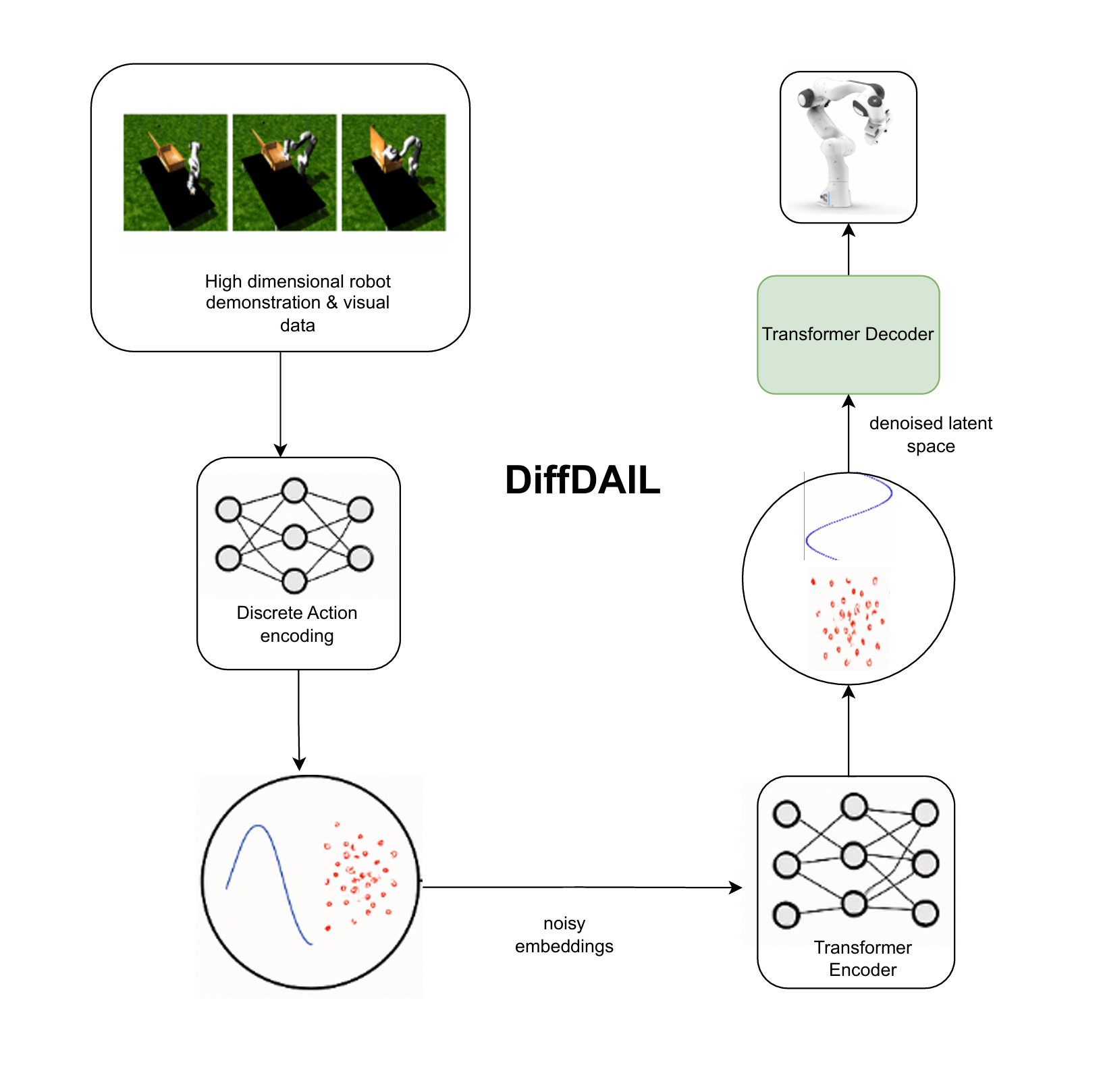
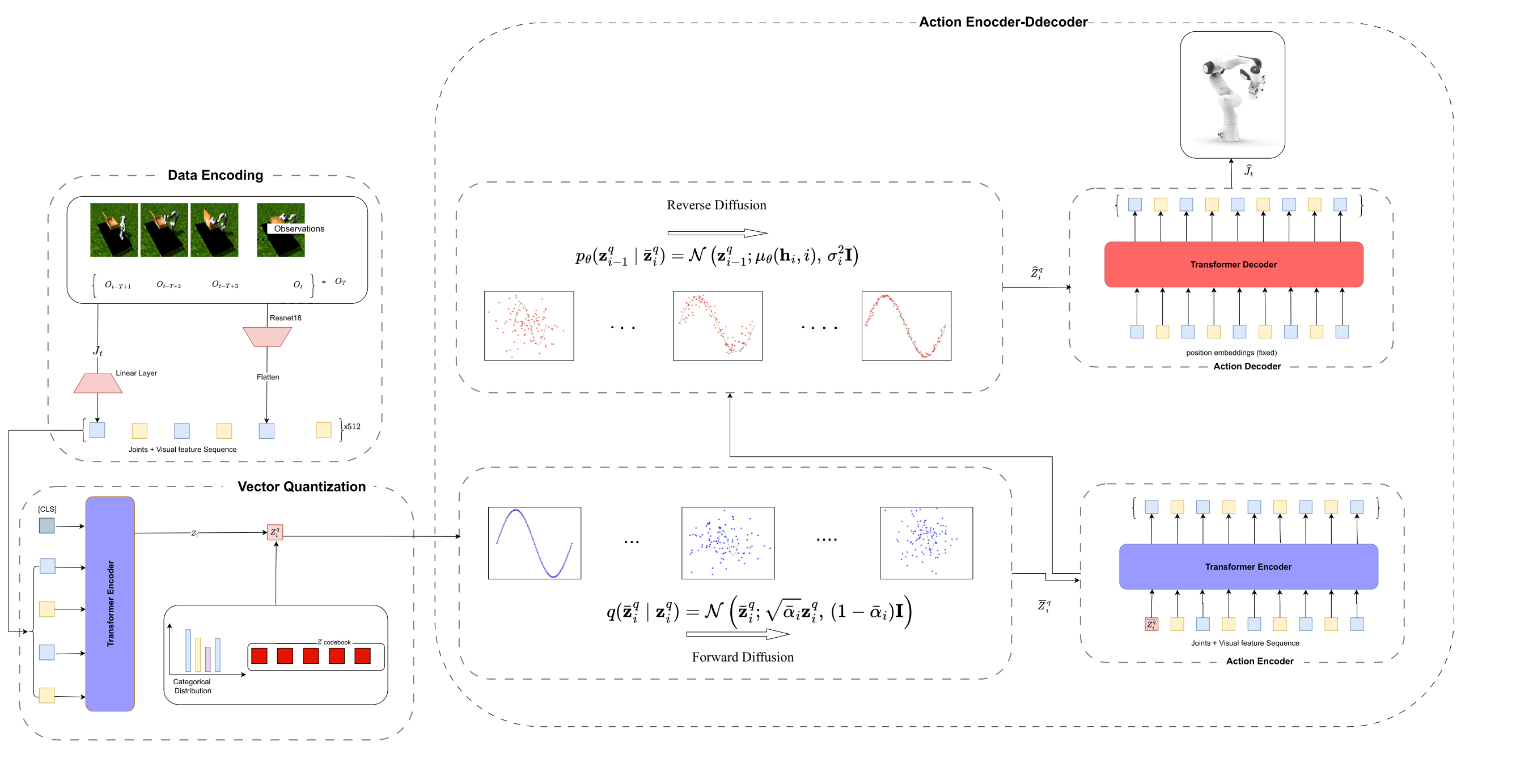
Project Website🔬 Methodology#
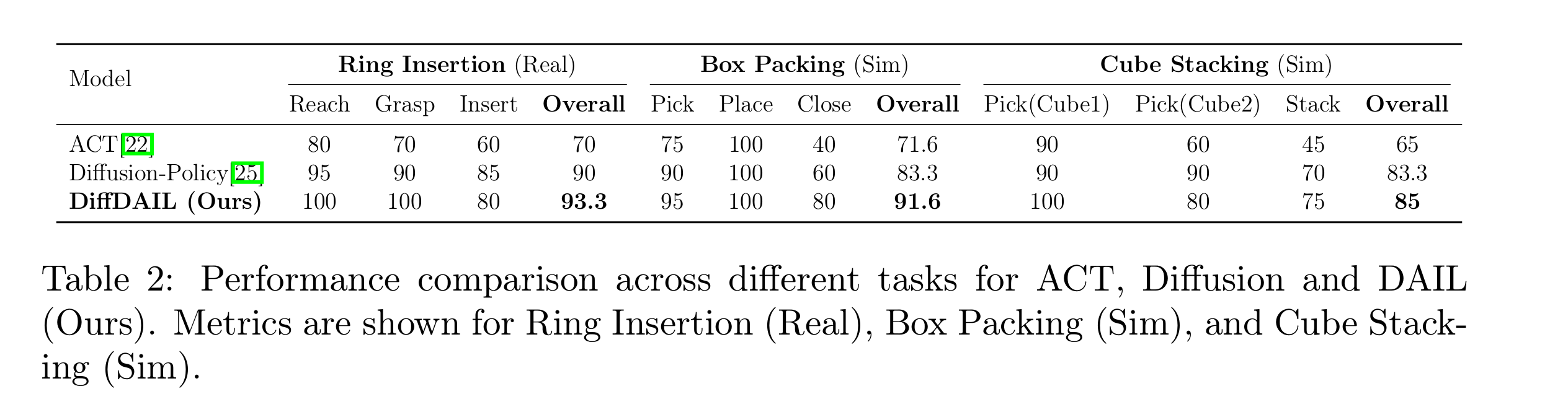
📊 Results#