Transformer Based Vision Guided Tissue Processing#
Overview#
This project demonstrates the automation of tissue packing using ViperX robotic arms and the Action Chunking Transformer (ACT) algorithm. A leader-follower setup was employed to collect demonstration data and train the ACT model for autonomous operation.
Hardware Configuration#
Leader-Follower System:
Leader: Two ViperX 300 S arms (750mm reach, 6 DOF, 750g payload) recorded tissue-packing motions.
Follower: Two ViperX Aloha arms mirrored leader movements via real-time joint position streaming at 50Hz.
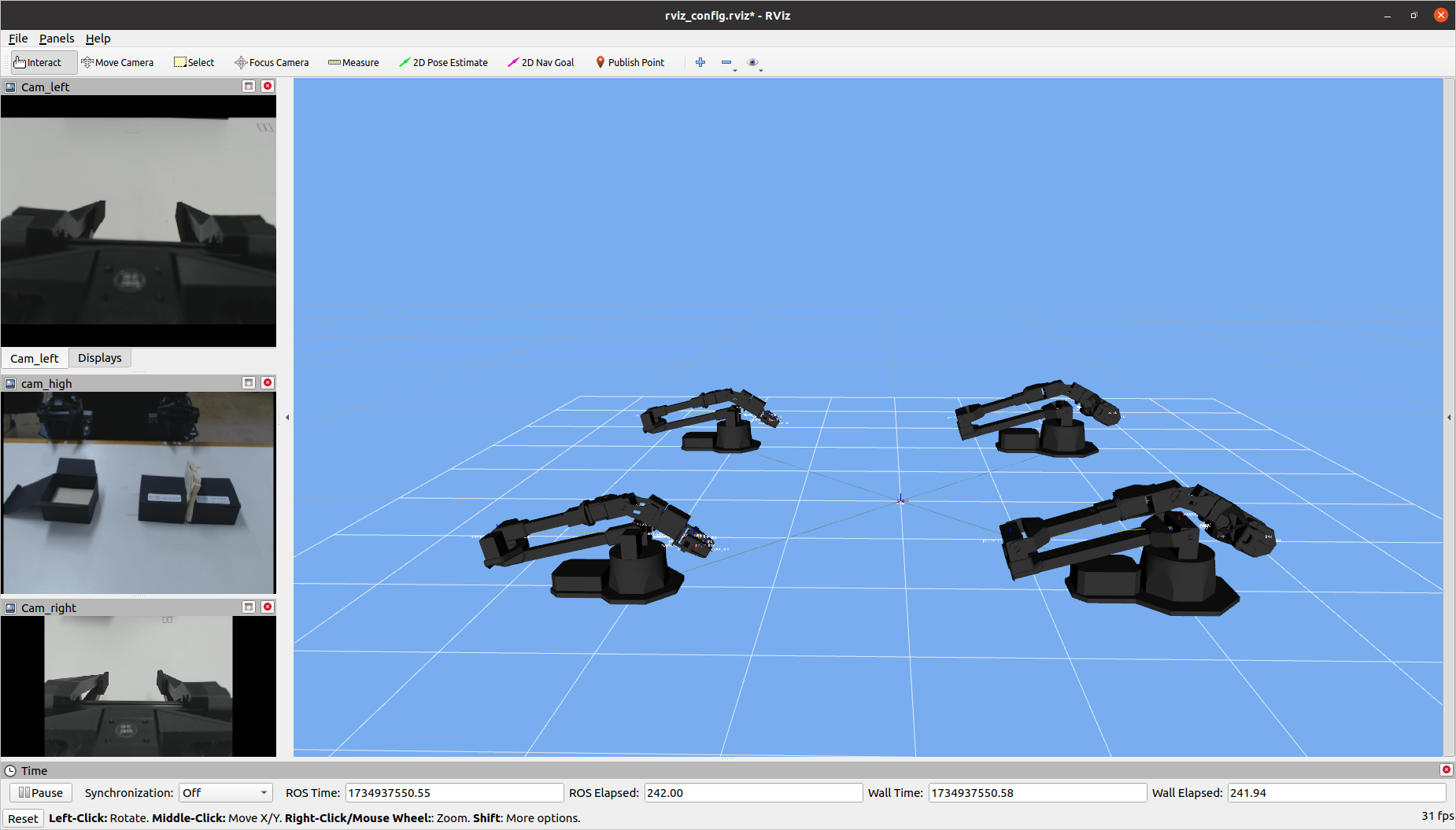
Dataset Generation#
Collected Data:
Joint angle sequences (from leader arms)
Gripper states (open/close)
Time-synchronized camera feeds (2 viewpoints)
Demonstration Style:
Teleoperated leader arms performed 100+ tissue-folding and box-packing sequences.
ACT Implementation#
Key Adaptations for Tissue Packing#
Chunk Size: 14 actions (0.16s horizon) balanced responsiveness and error correction.
Input Modalities:
HDF5 file contents:
- action: <HDF5 dataset "action": shape (149, 14), type "<f8">
- observations:
- images:
- top: <HDF5 dataset "top": shape (149, 480, 640, 3), type "|u1">
- qpos: <HDF5 dataset "qpos": shape (149, 14), type "<f8">
Transformer Architecture:
6-layer encoder (vision + proprioception fusion)
4-layer decoder for action sequence prediction
Training Protocol#
Loss: L1 reconstruction + KL divergence (β=0.5)
Augmentations:
Random lighting variations
Synthetic occlusions (simulate tissue wrinkles)
Joint position noise (σ=0.8°)
Results#
Metric |
Leader Performance |
ACT Follower |
|---|---|---|
Success Rate |
92.4% |
85.7% |
Cycle Time |
4.2s/item |
4.8s/item |
Positional Error (σ) |
0.5mm |
1.1mm |
Conclusion#
The system achieved autonomous operation with less than a 15% performance gap compared to human teleoperation, demonstrating ACT’s effectiveness for deformable object manipulation. Future work could integrate real-time haptic feedback and dynamic chunk-size adaptation.